

Does your database have leaky connections? It may be slowly killing your performance! Or fastly. Either way killing is bad.
Troubleshooting SQL Server is one of my favorite aspects of being a Database Administrator. You get to peel back layers, look at clues and piece together a story to help you point fingers(in the nicest way possible). Hopefully the fingers aren't pointed back at yourself. When memory pressure hits, it's often a known suspect. When it's not, that's when you're experience and analytical skills get put to the test, especially if you're in a web/conference bridge or going to see a movie.
Leaky Pools
When an application connects to a database it takes resources to establish that connection. So rather than doing this over and over again a connection pool is established to handle this functionality and cache connections. There are several issues that can arise if either the pool is not created with the same connection string (fragmentation), or if the connections are simply not closed/disposed of properly.
In the case of fragmentation, each connection string associated with a connection is considered part of 1 connection pool. If you create 2 connection strings with different database names, maxpool values, timeouts, or security then you will in effect create different connection pools. This is much like how query plans get stored in the plan cache. Different white space, capital letters all create different plans.
You can get the .NET pool counts from:
Performance Monitor> .NET data provider for SQL Server > NumberOfActiveConnectionPools
Another problem occurs if connections aren't closed or disposed of properly. These connections can exceed the default 100 connection pool limit and give you a nice application error. Or they can hold onto database resources and kill you slowly, like my daily commute. It could be as simple as as developer using a try/catch block without the finally to close the connection. Relying on the try section only to close the connection could be skipped by an exception.
The Slow Leak
We had an interesting intermittent issue with an application that would exhibit performance issues at seemingly random weekends spilling into the wee hours of Monday morning. Since this was happening outside of normal business hours, I wasn't directly involved in much of the real time troubleshooting. Initially a weekly application server reboot was implemented to help mitigate the original issue, per the vendor recommendation. This did help, but not for very long.
This application database on this instance also wasn't large by any means. In fact my old DBA manager(b|t) went so far as to call this a "chicken s!*t database". The fact that he is no longer my current manager factually makes him my old manager. This is not a joke about him being elderly, although I have heard some call him grandpa. I digress.
The usage patterns pointed to some reporting and heavy reads over some predictable dates. Using SQLSentry's SentryOne Performance Analysis historical feature I could see lots of key lookups, heavy reads, missing indexes, lots of scanning and HEAPS! Not surprising for some vendor apps though ammiright?!
The wait types were consistently memory related. An overnight colleague could see SOS_SCHEDULER_YIELD, which meant the thread was either waiting for a resource or exhausting the 4ms quantum and yielding control. The second wait they were seeing was RESOURCE_SEMAPHORE, which meant memory grant issues. All the pieces of information were pointing to some large scans that were confirmed in the query plans in SentryOne. Since this was a vendor application issue all we could do was throw more memory at it and give them the largest problem queries/stored procedures. This did indeed fix the issue again, but would soon prove to be a band aid to the real problem.
Something just didn't add up
After 2 weeks of chugging along with no issues, I decided to take a look myself on a quiet Thursday afternoon. All seemed ok. There were no active connections, and plenty of room in the Buffer pool so I decided to test a heavy load. I immediately saw RESOURCE_SEMAPHORE waits, CPU steadily increasing and the requested query not being granted any memory

What was going on? There was more than enough memory from the usage and work being done. And these "chicken s*!t databases" could all fit into the buffer pool.
Then it hit me after remembering a nasty PK violation I saw a few years ago that ballooned the SOSNODE memory clerk, which handles SQLOS exceptions among other things. The exact same symptoms were happening, but much slower. Something is stealing memory.
Looking at buffer descriptors, I saw all the pages associated with each DB, which didn't add up until I finally looked at memory clerks. What I saw was something I had never seen before. The MEMORYCLERK_SQLCONNECTIONPOOL was taking up over 60% of the entire available memory!
The SQLCONNECTIONPOOL was taking up over 18GB!

You're SQLCONNECTIONPOOL should never be multiple GBs, never mind 18! You can read HERE that anything over 1GB is no bueno.
Although I had never actually seen this issue before, I knew exactly what was causing it. The vendor app was most likely not closing connections. I looked quickly at all the sleeping connections and only found around 40, not massive connection pool leak seen in Michael J Swart (b|t) post HERE , but a leak none the less since this was during the customer's overnight window. Perhaps if this were used more heavily it would have presented itself more quickly making it easier to diagnose.
You can see some of the leaky goodness below with some connections being over 20 days old courtesy of sys.dm_exec_sessions. There are also a lot of similar read/write patterns in some of them as well. Very interesting.
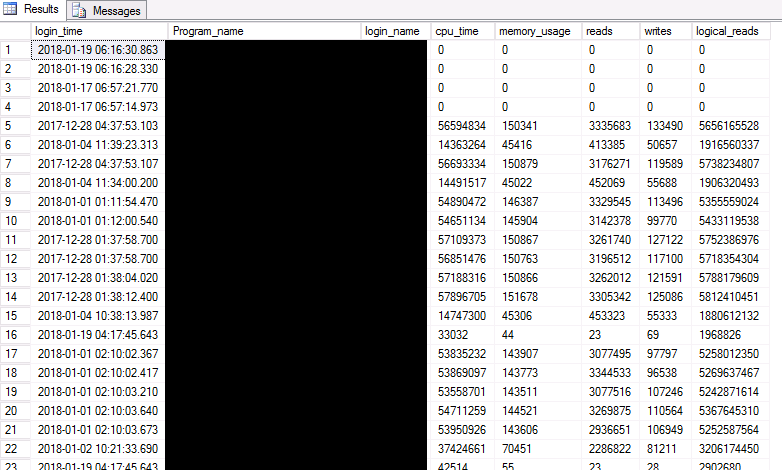
After seeing all of the evidence, I got in contact with the vendor to give them the news. We found the problem, but it's being caused by your application.
We restarted application services the next day, which obviously killed the CONNECTIONPOOL page count. By that time the CONNECTIONPOOL memory consumption was nearly 90%. I monitored that memory clerk throughout the day and again observed a slow steady suck of resources by the CONNECTIONPOOL. We are currently waiting for a fix. In the meantime we'll be cycling services when it hits a certain point. Boooo!
How no one else caught this, I have no idea. Maybe it's a weird edge case scenario we're so lucky enough to hit. At least we finally figured out the root cause. No wonder the vendor recommends application reboots every week!
Hopefully this helps someone discover their own leaky connections. If your memory consumption just isn't adding up, check the clerks and buffer descriptors! It could be exceptions inflating the SOSNODE, or it could be leaky connections slowly increasing your SQLCONNECTIONPOOL!